
商標登録で失敗しない|45区分一覧と注意点を徹底解説
2025-09-29
自動運転AIの技術革新と市場戦略|レベル3の限界とADASの最前線
2025-10-21特許ノイズとは?原因やAI活用による除去方法を解説

特許調査に携わる知財担当者にとって、「特許ノイズ」は避けて通れない課題です。
膨大な特許情報の中から本当に必要な文献だけを見つけ出す作業は、まるで砂漠で一粒の砂金を見つけるようなものです。
このノイズへの対応は、単に調査に要する時間や手間を減らす話にとどまりません。調査コスト全体や重要情報の見落としリスクを左右し、ひいては知財戦略に直結する重要なテーマです。
本記事では、まず「特許ノイズ」を定義し、その発生要因を整理します。次に、ノイズを減らす具体的な方法を紹介します。
最後に、近年注目されるAI活用がこの課題にもたらす変化についても解説します。
▼AIによる特許調査コスト削減についてはこちら
AIで特許調査のコストを1000分の1に|活用戦略を詳しく解説
特許検索における「ノイズ」とは
特許検索における「ノイズ」とは、検索結果に含まれてはいるが、検索目的に合致しない余分な情報や文献を指す概念です。
例えば、似たキーワードを含んでいても技術内容が異なる特許や、関連性の薄い分野の出願などがこのノイズに該当するでしょう。
一方で、本来は検索対象であるにもかかわらず、検索条件の限界によって結果に含まれなかった文献は「モレ(検索漏れ)」と呼ばれます。
つまり、ノイズは余分なヒット、モレは取りこぼしです。
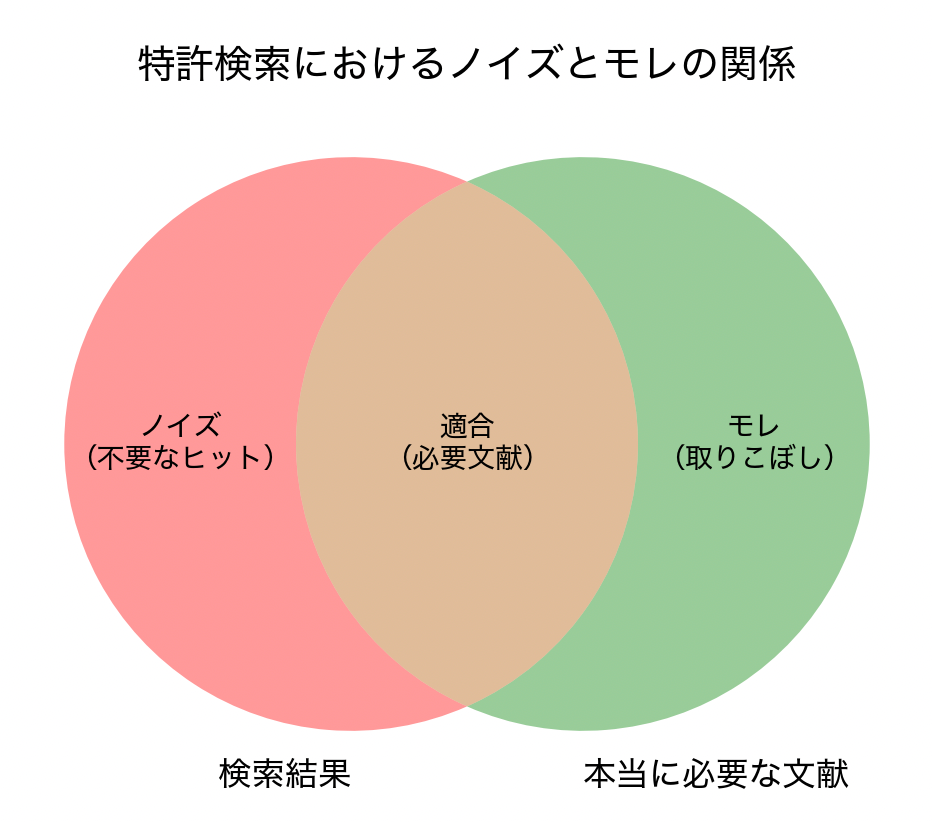
こうしたノイズとモレは、特許検索の「質」を評価する際に必ず意識されます。そこで、それらを数量的に捉えるために用いられるのが「再現率」と「適合率」という二つの指標です。
再現率は、探している特許文献をどれだけ網羅的に見つけられたかを示し、適合率は、検索結果のうち本当に必要な文献がどれだけ含まれているかを示します。
再現率と適合率はトレードオフの関係です。再現率を重視して検索範囲を広げれば、重要な特許を見落とすリスクは減りますが、無関係なノイズが大量に混ざり、適合率が下がります。逆に適合率を高めようと条件を絞ると、必要な文献を取りこぼすモレが発生します。
実務では、多少のノイズは許容してもモレを避けることが一般的です。なぜなら、モレは将来的に特許侵害訴訟や製品回収といった重大リスクに直結するからです。一方、ノイズは調査者の確認作業を増やすだけで、直接的に法的リスクを生むわけではありません。
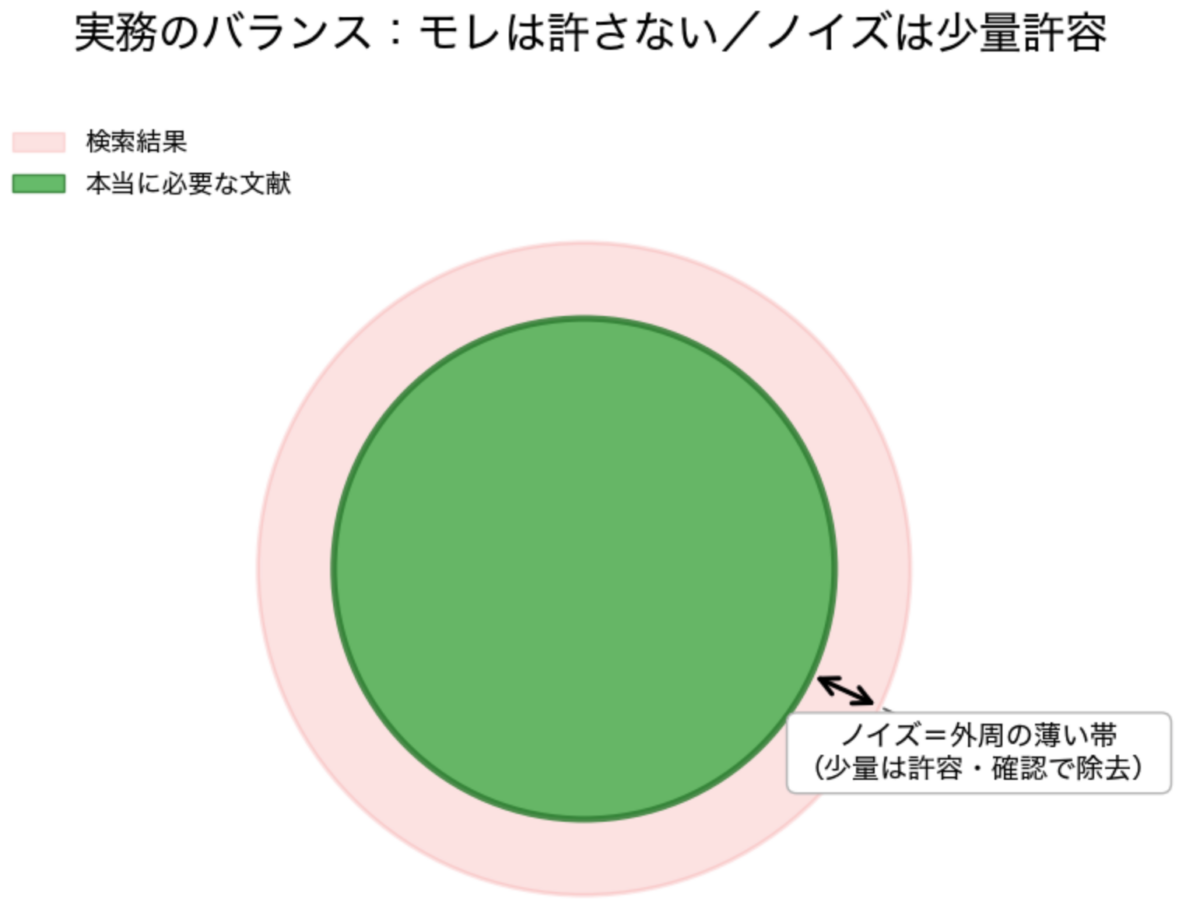
特に新製品のクリアランス調査(特許侵害の有無を確認する調査)のように、一件の見落としすら許されない場面では、再現率を最優先にして検索集合を広げます。
その結果、調査担当者は膨大なノイズ文献の確認作業に追われ、知財部門全体としても多くの時間と人員を割かざるを得ないのが実情です。
▼特許調査の基本についてはこちら
特許調査とは|効率的な進め方を徹底解説
▼特許侵害の予防と対策についてはこちら
特許侵害の要件と対策を徹底解説|事前予防から紛争解決まで
参考記事:
特許ノイズが発生する要因
特許検索では、意図しない文献が検索結果に混ざってしまう「ノイズ」を完全に避けることはできません。その原因は、大きく4つに分けて考えることができます。
| 要因 | 説明 | 例 |
| ① 言葉の曖昧さ | 多義語や翻訳の違いで無関係な文献が混ざる | cell=電池/細胞、ソース=源泉/調味料 |
| ② 検索式の不完全さ | 部分一致・ワイルドカードで余計な語を拾う | 「ハブ」で検索すると「プレハブ」もヒット |
| ③ 文書や制度の特徴 | 特許請求の表現や分類の違いで幅広く引っかかる | 「〜など」「〜に限らない」といった請求項表現、国ごとの分類差 |
| ④ 情報量とデータ誤り | 公開件数の膨大さやOCR・翻訳の誤りで混入 | 文字認識ミス、誤訳 |
まず、言葉そのものが曖昧なため起きるノイズです。
たとえば「cell」という単語は「電池」にも「細胞」にも使われますし、日本語の「ソース」も「源泉」と「調味料」の両方の意味を持ちます。こうした言葉の多義性や翻訳の違いによって、本来調べたい分野とは無関係の文献がヒットしてしまいます。
次に、検索式の作り方が不完全なために起きるノイズです。
検索範囲を広げるために部分一致やワイルドカードを使うと、関係ない語まで拾ってしまうことがあります。
例えば「ハブ」で検索すると「プレハブ」という全く別の技術が混ざってしまう、といった具合です。除外条件や近接条件を設定しなければ、意図していない文章まで検索結果に含まれてしまいます。
さらに、特許文書の書き方や制度の違いによって起きるノイズです。
特許は請求項を広くするために「〜など」「〜に限らない」といった表現を多用します。例えば、本来は「樹脂」を想定していても、「樹脂に限らない絶縁体」と書かれる場合があります。その結果、検索では不要な「絶縁体」関連の文献まで引っかかってしまうのです。
また、同じ技術でも国によって分類の付け方が違ったり、審査官ごとに解釈が異なったりするため、検索結果に一貫性がなくなります。
最後に、情報が膨大すぎるから避けられないノイズです。
世界中で毎年数百万件もの特許が公開されるため、ほんのわずかな曖昧さでも大量の誤ヒットにつながります。
さらに、スキャンデータの文字認識の誤りや、機械翻訳の不正確さによって、本来関係ない単語がデータベースに混ざり込み、結果として検索結果に不要な文献が加わってしまいます。
このように、言葉の曖昧さ、検索式の作り方、特許文書や制度の特徴、そして情報の膨大さが重なり合い、特許検索におけるノイズを生み出しているのです。
▼国際特許検索の調査戦略についてはこちら
国際特許検索とは|海外展開の失敗を防ぐ生成AI時代の調査戦略
参考文献:
- van der Pol, J.・Rameshkoumar, J.-P.|A method to reduce false positives in a patent query
- Freilich, J.|Patent Clutter
従来の特許ノイズの除去・削減方法
特許調査でノイズを削減するためには、検索式の工夫とスクリーニングの二つの手法を組み合わせることが重要です。
まず検索式の段階で無関係な文献をできるだけ減らし、調査対象に関わる文献を効率的に収集することが求められます。しかし、検索式を改善しても完全にノイズを排除することは難しく、そこで必要となるのがスクリーニングです。
スクリーニングには、自動処理によって文献を仕分けるオートスクリーニングと、専門家が内容を確認して精査するマニュアルスクリーニングがあります。
オートスクリーニングは大量の文献を効率的に処理するのに有効であり、マニュアルスクリーニングは技術的な本質を理解し、最終的な精度を担保する役割を果たします。
両者を適切に組み合わせることで、ノイズを効果的に削減し、効率的かつ信頼性の高い特許調査が可能です。
参考記事:
- Timo Kats, Peter van der Putten, Jan Scholtes|Relevance feedback strategies for recall-oriented neural information retrieval
- Shu Zhang, LiSha Zhang, Kai Duan, XinKai Sun|Research on Evaluation Methods for Patent Novelty Search Systems and Empirical Analysis
検索式の改善によるノイズ低減
特許ノイズ対策の第一歩は、検索式の段階でノイズを可能な限り減らすことです。
そのためには、調査対象を多角的に捉え、複数の観点から「小集合」を作成して検索を組み立てる方法が有効です。小集合とは、調査対象の発明を異なる切り口で小さな検索集合に分解し、それらを組み合わせていく手法を指します。
| 方法 | 内容 | 効果 |
| 小集合の作成 | 異なる観点ごとに小規模な検索集合(例:関節構造、安全制御、衝突検知センサー)を作成し組み合わせる | 無関係な特許を自然に除外し、関連性の高い文献を抽出できる |
| 分類(IPC/CPC)の活用 | 審査官が付与する技術分類を利用し、キーワード表記揺れに依存せず検索 | 用語の違いによる取りこぼしを防ぎ、精度を高められる |
| メタデータによる絞り込み | 出願年、国、出願人で制限(例:直近5年、JP、競合企業) | 最新動向や特定市場・企業の状況を的確に把握できる |
| NOT検索 | 「家庭用」「玩具」など不要分野を排除 | ノイズの大幅な削減 |
| 近接検索 | 「ロボット」と「安全制御」が近接して現れる場合に限定 | 関連性の高い結果を効率的に抽出できる |
| フィールド指定 | タイトル・要約に限定して検索 | 発明の本質的情報に集中し、雑多な用語を回避 |
例えば、製造業で用いられる産業用ロボットの技術を調べるケースを想定しましょう。
最初から「産業用ロボット AND センサー AND 安全制御」といった包括的な検索を行うと、家庭用ロボットや玩具の特許まで混在し、ノイズが増える一方で、必要な技術文献を取りこぼす可能性も生じます。
これに対して、「関節構造に関する技術」「作業環境に応じた安全制御」「衝突検知センサー」といった観点ごとに小規模な検索集合を作成し、それらを掛け合わせたり比較したりする方法があります。
こうすることで、無関係な特許を自然に除外しつつ、関連性の高い文献を確実に抽出できるでしょう。
さらに、キーワードのみに依存せず、IPC や CPC といった特許分類を組み合わせることで、検索の精度を一段と高められます。
特許分類は、出願時に審査官が技術内容に基づいて付与するラベルであり、用語の表記揺れや言い換えに左右されません。
例えば「協働ロボット」という語を含まない特許でも、関連する IPC に分類されていれば検索結果に含められるため、不要なノイズを避けつつ必要な文献を取りこぼしにくくなります。
加えて、出願年・国・出願人といったメタデータによる絞り込みも有効です。
例えば最新動向を把握したい場合は出願年を直近 5 年に限定することで、古い技術や時代遅れの出願を除外できます。日本市場向けの動きを把握するなら出願国を「JP」に絞り込み、競合他社の研究開発状況を調べたい場合は出願人を特定企業に限定するといった活用も可能です。
さらに、NOT 検索を使えば「家庭用」や「玩具」といった不要分野を排除できます。
また、近接検索を利用すれば「ロボット」と「安全制御」が文中で近接して現れる特許だけを抽出できるため、関連性の高い結果を効率的に得られます。
加えて、検索対象をタイトルや要約といったフィールドに限定する方法も有効です。文献全体に散在する雑多な用語を避け、発明の本質を端的に示す情報に集中できるためです。
このように分類・メタデータ・検索演算子を組み合わせることで、単なるキーワード検索では拾ってしまう無関係な結果を大幅に減らし、必要な文献を高い精度で抽出できます。
▼特許分類FIの活用方法についてはこちら
特許FIとは|分類の整理・利用メリットを徹底解説
参考記事:
- Timo Kats, Peter van der Putten, Jan Scholtes|Relevance feedback strategies for recall-oriented neural information retrieval
- Shu Zhang, LiSha Zhang, Kai Duan, XinKai Sun|Research on Evaluation Methods for Patent Novelty Search Systems and Empirical Analysis
スクリーニングによるノイズ除去
| オートスクリーニング | マニュアルスクリーニング | |
| 目的 | 自動で並べ替え・束ねて確認順を最適化 | 最終の目視確認で見落とし防止 |
| 見る要素 | 出願人・分類・引用関係・キーワード類似 | クレーム・明細書・図面・用語解釈 |
| 使いどころ | 初期の粗選別と重複整理 | 重要案件・曖昧案件の確定 |
| 強み | 速い、負荷減、偏りを平準化 | 精度担保。複雑開示に強い |
| 注意点 | 図面中心分野などで誤判定あり | 手間がかかる。基準の整備が必要 |
| 出力 | 優先度リスト/クラスター | 採否判断と根拠メモ |
検索で得られた特許集合には依然として多くの不要文献が含まれるため、それらを効率的に仕分ける「スクリーニング」はノイズ対策の要となります。
手法は大きく二つに分けられ、自動的に優先順位を付ける「オートスクリーニング」と、人間が精査する「マニュアルスクリーニング」です。
両者を組み合わせることで、効率と精度を両立させることができます。
オートスクリーニングの活用と手法
オートスクリーニングとは、特許検索データベースや分析ツールに搭載された機能を活用し、システムが自動で文献に優先順位を付与して並べ替える仕組みです。
| 代表例 | 効果 |
| キーワード頻度 | 課題や解決が近い文献を上位化して読む数を圧縮 |
| 引用・被引用ネットワーク 、出願人・権利者重み | 重要度の高い文献を優先提示して見落とし抑制 |
| ファミリー統合 、類似特許束ね 、自動クラスタリング | 重複調査を回避し不要トピックを一括除外 |
| 関連性フィードバック学習 | 人手評価を反映して次回ランキング精度を向上 |
出願人や権利者の名称、特許分類、引用・被引用の関係、キーワードの出現頻度など、複数の指標を組み合わせて点数化し、「どの特許から確認すべきか」を提示します。
この仕組みを導入すれば、すべての明細書を最初から読む必要はなく、まずは重要度の高い特許から確認を進められます。結果として、調査者の負担を大きく軽減できます。
これは調査効率を大幅に向上させると同時に、担当者の集中力やモチベーションを維持する点でも効果的です。
さらに、検索結果を自動的にグループ化し、不要なグループを除外できる「クラスタリング」や、同一発明に基づく複数国での出願(ファミリーパテント)、あるいは類似特許をまとめる仕組みを活用すれば、重複調査を避けることができます。
これらを組み合わせることで、調査の効率化に加え、調査範囲に生じやすい抜けや偏りを防ぐことにもつながります。
参考記事:
- Timo Kats, Peter van der Putten, Jan Scholtes|Relevance feedback strategies for recall-oriented neural information retrieval
- Shu Zhang, LiSha Zhang, Kai Duan, XinKai Sun|Research on Evaluation Methods for Patent Novelty Search Systems and Empirical Analysis
マニュアルスクリーニングの重要性
マニュアルスクリーニングは、オートスクリーニングでは判断が難しい文献を最終的に精査する段階であり、調査の質を保証する役割を担っています。
| 代表例 | 効果 |
| クレーム必須要件の突合 | 関連の有無を最終確定して見落としを防止 |
| 図面、 回路記号 、化学式 | 文章に出ない核心構成を把握して誤判定を回避 |
| 同義語 、略語 、分野特有表現 | 表現差を平準化して実質一致を正しく判定 |
| 判定根拠の記録 → 関連性フィードバック | 次回以降の検索やランキングを継続的に改善 |
特許調査において最も避けるべきなのは「必要な文献を見落とすこと」であり、これは自動処理だけでは防ぎきれないリスクです。そのため、最終判断は必ず人間の専門家による確認が求められます。
特に、特許文献は明細書やクレームが長大で複雑であり、図面や回路記号、化学式などが重要な意味を持つことも少なくありません。
こうした場合、単純なキーワードやスコアリングでは関連性を正しく判断できず、専門知識をもった人間が内容を読み解く必要があります。たとえば電気分野の特許では、略語や図面中心の開示が多く、AIによる自動処理の精度が低下することが知られています。
さらに、マニュアルスクリーニングは「質の担保」にとどまらず、検索システムの改善にも寄与します。人間が精査して関連ありと判断した文献は、関連性フィードバックとしてシステムに再投入され、次回以降の検索やランキングの精度を高める材料となるのです。
この点で、マニュアルレビューは単なる受動的な確認作業ではなく、調査全体を進化させるための能動的なプロセスでもあります。
参考記事:
- Timo Kats, Peter van der Putten, Jan Scholtes|Relevance feedback strategies for recall-oriented neural information retrieval
- Shu Zhang, LiSha Zhang, Kai Duan, XinKai Sun|Research on Evaluation Methods for Patent Novelty Search Systems and Empirical Analysis
AIによる特許検索のノイズ除去・削減効果
AIは特許調査の効率と質を大きく変えつつあります。従来の検索では膨大な不要文献が混じり、その選別に多くの時間を費やすことが調査者の大きな負担となっていました。
この原因は、検索がキーワードや分類に依存していた点にあります。同義語を十分に扱えず検索漏れが生じ、多義語のために無関係な分野の文献が混入するなど、ノイズの回避が難しかったのです。
AIはこうした限界を克服します。人間が関連性を確認した特許を学習し、抽出した特徴を基に新しい文献の関連度を判定します。さらに、文脈や技術的な意味を理解することで、従来型検索が苦手とした曖昧さを処理できるのです。
研究の結果、この仕組みを導入すると、必要な特許を見落とすことなく読むべき文献を最大で約6割削減できることが示されています。これにより調査者は本当に確認すべき情報に集中できるようになります。
具体的には、「半導体」と「半導体デバイス」を同義語として扱い検索漏れを防ぐ。「cell」が電池か細胞かを文脈で判別して不要分野を除外する。「放熱フィン」に関してはアルミ板と銅板を区別して対象に絞り込む、といった処理が可能です。
従来の文字列検索では難しかった判断を自動化できる点は大きな進歩です。このようにAIは単なる文字列一致を超え、言葉や技術の意味を理解した検索を実現します。
▼AIを活用した特許調査についてはこちら
AI活用で特許調査はここまで進化する
参考記事:
- Kats, T.・van der Putten, P.・Scholtes, J.|Relevance feedback strategies for recall-oriented neural information retrieval
- U.S. Patent and Trademark Office (USPTO)|Artificial intelligence and patent data: 2023 report
- Bekamiri, H.・Hain, D. S.・Jurowetzki, R.|PatentSBERTa: Hybrid model for patent distance and classification using augmented SBERT
- Research on Evaluation Methods for Patent Novelty Search Systems and Empirical Analysis Shu Zhang, LiSha Zhang, Kai Duan, XinKai Sun
まとめ
特許調査におけるノイズは避けられない課題ですが、その要因を理解し、検索式の工夫やスクリーニングを組み合わせることで着実に抑えることができます。
さらに近年はAIの発展によって、従来は困難だった文脈の理解や曖昧さの処理が可能となり、効率と精度の両立が現実のものとなりつつあります。
ノイズに振り回されるのではなく、適切な方法と技術を活用して調査を進化させていくことが、知財を扱う者に求められる姿勢といえるでしょう。
▼特許調査の効率化とコスト削減についてはこちら
特許調査の費用軽減|生成AIがもたらす効率化と省コスト化
エムニへの無料相談のご案内
エムニでは、製造業をはじめとする多様な業種に向けてAI導入の支援を行っており、企業様のニーズに合わせて無料相談を実施しています。
これまでに、住友電気工業、DENSO、東京ガス、太陽誘電、RESONAC、dynabook、エステー、大東建託など、さまざまな企業との取引実績があります。
AI導入の概要から具体的な導入事例、取引先の事例まで、疑問や不安をお持ちの方はぜひお気軽にご相談ください。

引用元:株式会社エムニ




