

深刻化する人材不足と技術伝承の課題に直面する製造現場では、異常値検出システムへの注目が高まっています。24時間365日の異常監視による品質向上、予知保全によるコスト削減、ベテランの暗黙知のデジタル化など、その効果は多岐にわたります。本稿では、統計的手法から機械学習まで、異常値検出の実践的知識を徹底解説。異常値検出システムの設計から運用、改善まで、現場での導入シナリオに沿って具体的なノウハウをお届けします。
異常値検出とは
異常値検出とは、大量のデータから、統計や機械学習といった手法を用いて、通常の動きから大きく外れたデータを見つけ出すプロセスです。
異常値検出は単なる異常箇所の発見にとどまりません。異常値の検出は、機器故障や不正侵入といった技術的な問題から、不正取引や製造上の欠陥、さらには新しい発見につながる興味深い現象まで、様々な事象を示唆することができるのです。このように、異常値検出システムは、設備監視、品質管理、安全性確保、経営判断など、幅広い分野で重要な役割を担う可能性を秘めていると言えるでしょう。
なお、異常値と似た言葉に「外れ値」という言葉があります。
外れ値とは、データセットから大きく逸脱している値の総称を指します。外れ値には測定誤差など様々な原因が考えられますが、分析に悪影響を与える可能性があるため、除外・変換といった特別な取り扱いをする必要があります。ただし、外れ値には重要な情報が含まれている場合もあるので、取り扱いには注意しましょう。
一方で、異常値は外れ値の中でも原因が特定できるものを指します。原因が特定できるため、多くの場合、異常値は分析からは除外されます。
異常値検出の4大手法
異常値検出には大きく4つの手法(統計的手法、クラスタリング手法、時系列分析手法、機械学習手法)が存在します。ここでは4つの手法それぞれについて説明します。
1. 統計的手法
統計的手法は、最も基礎的かつ信頼性の高い異常値検出のアプローチとして広く活用されています。データの分布特性を活用した手法であり、その科学的な裏付けと解釈のしやすさから、多くの現場で採用されているのです。また、大規模なデータセットの分析にも対応可能です。
統計的手法の根幹となるのが正規分布の概念です。製造過程で得られる多くのデータは、理想的条件下では正規分布に従う傾向があります。正規分布では、データが平均値を中心に左右対称に分布し、平均値から離れるほどデータの出現頻度は低下します。統計的手法では、この平均値からの「ずれ」を定量的に評価することで、異常値を特定するのです。
最も一般的なのが「3σ(シグマ)法」。この手法では、データの平均値から標準偏差の3倍(3σ)を超えて外れたデータを異常値と判定します。理論上99.7%のデータが含まれる範囲を正常とみなし、その範囲外のデータを異常として検出するため、誤検出を抑えつつ明確な異常を捉えることができます。
一方、データのばらつきが非対称な場合などには、「四分位範囲(IQR)」による検出が有効です。この手法では、データを小さい順に並べ、25%位置(第1四分位数)と75%位置(第3四分位数)の差をIQRとし、この1.5倍の範囲を超えて外れたデータを異常値として検出します。
2. クラスタリング手法
クラスタリング手法は「正常なデータは互いに近い位置に密集する傾向がある」という原則に基づいています。この基本的な考え方のもと、データポイント間の「距離」と「密度」という2つの重要な概念に基づいて異常を検出します。
クラスタリング手法の大きな利点は、多次元データへの適用が容易なことです。これにより、温度、圧力、振動、音響など、複数のセンサーデータを組み合わせた異常検知が可能になります。また、データ間の非線形な関係性も自ずと考慮することが可能に。これはデータポイント間の距離を計算する際に直線的な関係性に縛られないためです。
クラスタリング手法で代表的なのが「K近傍法」になります。この手法では、各データポイントについて、最も近い K個の近傍点までの距離を計算します。正常なデータポイントは近くに多くの近傍点を持つのに対し、異常値は他のデータポイントから離れた位置に存在するため、近傍点までの距離が大きくなるのです。例えば、K=5と設定した場合、最も近い5つのデータポイントまでの平均距離が、全体の平均的な距離と比べて著しく大きいものを異常として検出できます。
他には「Local Outlier Factor (LOF)」という手法も存在します。LOFでは、データポイントの局所的な密度を考慮に入れた異常度を計算可能です。具体的には、あるデータポイントとその近傍点の密度を比較し、周囲と比べて著しく密度が低いポイントを異常として検出します。この手法はデータの分布が均一でない場合に特に有効です。
3. 時系列分析手法
製造過程で生じるデータの多くは時間に伴って変化する時系列データです。時系列分析手法では、時間的に変化するパターンを認識し、そこからの逸脱を異常として検出します。
時系列データには、一般的に3つの重要なパターンがあります。長期的な変化傾向を表す「トレンド」、季節ごとに繰り返される「季節性」、そして季節ではない一定期間ごとに現れる「周期性」です。これらの要素を考慮して分析を行う必要があります。
時系列分析手法の重要な特徴は、データポイント間の時間的な関係性を考慮できることです。例えば、ある時点での異常は、その前後の値にも影響を与える可能性があります。このような時間的な依存関係を考慮することにより、高精度な異常検知が可能となるのです。また、時系列分析手法は、製造ラインのリアルタイムモニタリングにも適しています。新しいデータが得られるたびに予測値との乖離を評価し、即座に異常を検知することが可能になるのです。
時系列分析で代表的なのが「移動平均法」です。この手法では、直近の一定期間のデータの平均値を計算し、新しいデータポイントがその平均から大きく外れた場合を異常と判定します。特に、急激な変化の検出に効果的であり、リアルタイムでの異常検知に適しています。
また、より高度な手法として「STL分解」があります。この手法は、時系列データをトレンド成分、季節成分、残差成分に分解し、残差成分が通常の範囲を超えて大きい場合を異常として検出できます。この方法は、複雑な時間パターンを持つデータの異常検知に特に有効です。
4. 機械学習手法
機械学習手法では、大量のデータから自動的にパターンを学習し、高精度な異常値検出を行うことが可能です。
この手法の利点は、人手による監視や分析では見落としがちな微細な変化、複数の要因が絡み合った複雑な異常など、従来の異常値検出の手法では捉えきれなかった異常値を自動的に検出できることです。また、機械学習を活用した異常値検出では、24時間365日一貫した基準で監視を続けることが可能です。
さらに、機械学習手法には、新しい異常値パターンへの適応力が高いという特徴があります。製造工程の変更時にも、新しいデータで再学習を行うことにより、柔軟に対応できます。また、検出精度は運用とともに向上していき、誤検知の削減と検出精度の向上を継続的に図ることができます。
代表的な手法の一つが「オートエンコーダー」です。この手法は、入力データを圧縮・再現する過程で、正常なデータの特徴を学習します。再現誤差が大きいデータを異常として検出することで、複雑な異常パターンも捉えることができるのです。
もう一つの有力な手法が「Random Forest」です。この手法は、複数の決定木を組み合わせることで、高い精度の異常検知を実現します。データの特徴をツリー構造で表現するため、どの要因が異常判定に影響したのかを理解しやすいことが大きな利点です。
異常値検出システムを導入する5つのメリット
異常値検出システムを導入することにより多くのメリットが得られます。ここでは5つのメリットについて詳しくみていきましょう。
1. コスト削減
異常値検出システムの導入は、製造現場における様々なコスト削減を実現します。
最も大きく効果が表れるのは、製造設備の予知保全の実現による設備保全コストの削減です。従来の定期保全や事後保全と比較して、設備状態を常時監視することで状態ベースでの保全を実現。故障の予兆を早期に発見できます。また、生産ラインの突発的な停止を防ぐことにより、余分な修理費用や製造機会の損失を最小限に抑えることが可能です。
さらに、設備保全と品質管理の各工程において、異常検知や品質検査が自動化されることにより、人員配置を最適化、人件費の削減が期待できます。
異常検知システムの導入には、ある程度の設備投資が必要となりますが、設備保全費や人件費の削減効果を考慮すると、通常数年で投資回収することが可能です。特に、24時間稼働の製造ラインでは、省人化による効果が顕著に表れる場合も多くあります。
2. 属人化の解消・技能伝承の実現
異常値検出システムの導入は、製造業の長年の課題である業務の属人化解消と技能伝承の実現に大きく貢献します。
ベテラン従業員が長年の業務で培った暗黙知をデータ化することにより、標準化された判断基準を確立。特定の従業員に依存した検査体制から脱却できます。
また、異常検知システムは若手作業員の育成にも大きな力を発揮します。例えば、異常値が検出された際には、システムが根拠となるデータと対応手順を明確に示すことにより、経験の浅い従業員でも異常への対応が可能となるでしょう。
熟練作業者の退職を目前に控えた製造現場において、異常値検出システムの導入による技能伝承の仕組みづくりは、事業継続の観点からも急務となっているのです。
3. 品質管理体制の強化
異常値検出システムは、製造現場の品質管理体制を強化します。
製造工程で生じるデータをリアルタイムで監視・記録することにより、製品一つ一つの製造過程を完全に追跡できるトレーサビリティを確保できます。これにより、品質問題が発生した場合でも、問題の発生時点や工程を即座に特定でき、影響範囲を最小限に抑えることが可能です。
また、目視検査やマニュアルチェックに依存していた従来の品質管理から、センサーとAIによる24時間稼働の監視体制へと進化することで、作業者の疲労や注意力低下によるヒューマンエラーを大幅に削減できます。微細な品質異常の検出率が向上し、検査工程での不良品の発見精度も大きく改善されるでしょう。
さらに、品質データの可視化と異常の即時検知により、取引先への品質報告もより正確かつ迅速になります。これは品質への信頼性向上につながり、新規案件の受注や取引拡大にも貢献するでしょう。加えて、検査や品質のデータ蓄積および分析により、製造プロセスの継続的な改善が可能に。より強固な設備・品質保証体制が構築できるでしょう。
4. データドリブンな意思決定の実現
異常値検出システムの導入は、製造現場における意思決定プロセスを大きく変化させます。
例えば、設備点検のタイミングや製品検査の合否判定において、明確な数値基準に基づく判断が可能となり、個人間や部署間、工場間での判断基準の統一も実現できます。このように、現場の経験や勘に頼っていた判断を、客観的なデータに基づいて行えるようになるのです。
また、異常値検出のシステム化は、より戦略的な経営判断を支援します。具体的には、製造工程のパラメータ最適化や、品質向上施策の効果検証などの場面で、データに基づく客観的な評価により、業務改善効果を定量的に把握することが可能になるでしょう。
5. 業務効率の向上
異常値検出をシステム化することにより、製造現場における業務効率は大きく向上します。
まず、従来は従業員が目視による定期点検で行われていた検査業務が自動化され、従業員の精神的・肉体的負担を大幅に軽減。これにより、従業員はより創造的な業務に注力できるようになります。
また、システムによる24時間365日の常時監視により、夜間や休日における異常の見逃しリスクが解消されます。さらに、遠隔モニタリング機能により、必ずしも現場に常駐する必要がなくなり、在宅勤務など柔軟な働き方が可能となるでしょう。
加えて、異常値データのデジタル化により、報告書作成や情報共有が効率化。これまで手作業で行われていた異常記録の文書化や関係者への報告が自動化され、意思決定スピードの向上が期待できます。
異常値検出を実装するまでの5つのステップ
異常値検出システムの実装は以下に示す5つのステップに分けられます。データ収集から継続的モニタリングまで、効果的な異常値検出を実現するプロセスを見ていきましょう。
1. データ収集と前処理
異常値検出の成否を左右するデータ品質。まず、異常値検出に有効なデータソースを見極める必要があります。設備に搭載したセンサーからの生データだけでなく、製造実績や品質検査データ、さらには作業日報なども含めて検討しましょう。
データ品質を高める工夫も不可欠です。サンプリング頻度は多ければよいというものではなく、検知したい異常の特性やデータ保存コストを考慮して最適化しましょう。また、現場で避けられない欠損値やノイズについては、データ補完による対処が有効です。
さらに、収集したデータから異常を効果的に検出するには、適切な特徴量の設計が不可欠となります。平均値や標準偏差などの基本統計量に加え、トレンドや季節性といった時系列の特徴を抽出しましょう。また、センサーの数が多い場合は主成分分析などで次元を削減し、計算効率を向上させることも有効です。加えて、特徴量を比較可能な尺度に標準化することで、異常検知の精度向上が期待できます。
2. 適切な異常値検出手法の選択
異常値検出手法の選定では、まず、データの性質を見極める必要があります。例えば、単一センサーの時系列データなのか、複数センサーの相関を考慮すべき多変量データなのかで、適用可能な手法が大きく変化するのです。
また、見逃しや誤検知が発生した際の影響の大きさを考慮し、求められる検知精度を明確化することが重要です。品質や安全に直結する重要工程では高精度な検知が必須ですが、それ以外では過剰な精度追求は却って運用コストを増大させる可能性があります。また、リアルタイム検出が必要な工程では、計算量の少ない統計的手法が現実的な選択となるでしょう。
さらに、それぞれの異常値検出手法の特徴を考慮することも不可欠です。例えば、統計的手法は予測過程の説明性に優れ、現場での理解・運用が容易です。一方で、説明性には劣りますが、複雑なパターンの検出には機械学習手法が効果的です。あるいは、両者のメリットを活かしたハイブリッドアプローチが有効な場合もあります。
3. 異常値検出システムの設計と評価
システムの設計段階では、現場での実用性を十分に考慮しましょう。アーキテクチャの選定では、単純な統計的手法から複雑なディープラーニングまで、その製造工程に最適な手法を見極めます。過度に複雑な構造は、運用・保守の負担となるので注意が必要です。
異常値検出モデルの学習に際しては、正常データの収集は比較的容易である一方で、異常データは実際の製造現場では限られており収集が困難な場合があります。そこで、正常データの分布から外れたものを異常とみなす「外れ値検知」の考え方を採用するケースも多いことに留意しましょう。
さらに、性能評価では、見逃し(偽陰性)と誤検知(偽陽性)のバランスが重要です。製品品質や設備安全に関わる重要な異常の見逃しは回避すべきですが、些細な変動での過剰検知は現場の信頼を損ねる可能性もあるためです。また、ノイズや季節変動など、様々な外部要因に対するシステムの堅牢性も確認する必要があるでしょう。
4. 閾値の設定と調整
閾値設定は、異常値検出システムの実効性を左右する重要な工程です。初期閾値は、正常データの統計的分析(平均±3σなど)を出発点としつつ、現場の業務要件や許容できるリスクレベルを反映させて決定します。また、異常の重要度に応じて複数の閾値を設定し、注意・警告・緊急停止など、段階的なアラートを設計することで、現場での対応に優先順位をつけやすくなります。
また、運用開始後は、現場からのフィードバックをベースに閾値を継続的に調整することが重要です。誤検知が多すぎればシステムの信頼性が損なわれ、見逃しが多すぎれば設備や品質の安全性が脅かされます。このバランスを取るため、定期的な性能評価と閾値調整のサイクルを確立することが求められます。現場の運用実態に合わせて、季節変動や製品切り替えなども考慮した柔軟な閾値管理を行いましょう。
5. システム統合と継続的なモニタリング&改善
異常値検出システムを既存の製造システムや品質管理システムと適切に統合することで、現場での実用性が高まります。アラート通知は、重要度に応じて適切な担当者に通知する仕組みを構築し、直感的なインターフェースにより異常内容や対応手順をわかりやすく表示することが重要です。
また、実際の運用においては、システムの健全性を示す指標(検知精度、応答時間など)を定め、定期的なモニタリングを行います。特に重要なのは、誤検知や見逃しが発生した際の原因分析とフィードバックのプロセスです。インシデント対応のフローを明確化し、現場で適切に対処できる体制を整えましょう。
さらに、継続的改善の観点からは、定期的なモデルの再学習や新しい特徴量の追加を検討することが重要です。製造条件の変更や新製品の導入など、現場の変化に応じてシステムを柔軟に進化させることで、長期的な有効性を維持できます。また、成功事例を他のラインや工場へ水平展開することで、全社的な改善効果を最大化しましょう。
異常値検出における5つの課題と対策
異常値検出システムの導入により数多くのメリットが得られる一方で、いくつかの課題も存在します。ここでは5つの課題と、それらに対する対策について詳しく解説します。
データの質と量が与える影響
異常値検出の精度を決定づける最重要要素である、データの「質」と「量」。
まず、データの「量」の観点では、異常値検出モデルの学習には十分な量のデータが不可欠です。製造現場では、時間帯や曜日、季節などによって設備の稼働状態が変化するため、「正常な状態」の定義も一定ではありません。そのため、様々な条件下での正常データを収集し、モデルに学習させる必要があるのです。データ量が不足していると、限られた条件でしか正常状態を判断できず、想定外の状況で誤った異常検知を行ってしまう可能性が高くなるでしょう。
一方、データの「質」の観点では、センサーの故障やキャリブレーションのズレ、通信エラーによる欠損値、作業者の手入力ミスなど、様々な要因によりデータの品質が損なわれる可能性があります。このような品質が低いデータを学習に使用すると、システムは誤った判断基準を形成してしまうリスクがあるのです。
そのため、異常値検出システムの導入を検討する際は、まず十分な量のデータを収集できる体制を整えると同時に、収集したデータの品質を担保するための仕組み作りが重要となります。具体的には、センサーの増設や測定頻度の最適化、データクレンジングのプロセス構築などが必要となるでしょう。
誤検知と未検知のリスク
異常値検出における重要な課題に、「誤検知」と「未検知」のリスク管理があります。この2つは互いにトレードオフの関係にあり、両者の適切なバランスを取ることが運用上の大きな課題となります。
誤検知とは、正常な状態を異常と誤って判断してしまうケースです。例えば、製造ラインの一時的な負荷変動を設備の故障と誤って判断し、生産ラインを停止させてしまうようなケースが該当します。こうした誤検知が頻発すると、不要な生産停止や点検作業が発生し、生産効率の低下やコストの増加を招きかねません。
一方、未検知は異常が起こっているにも関わらず、それを見逃してしまうケースです。製造設備の異常を見逃すことにより、重大な設備故障や品質不良につながる可能性があります。特に製造業では、一度の重大事故や品質問題が、企業の多大な損失や価値の低下を招きかねません。
このジレンマを解消するためには、まず業務上の優先順位を明確にしたうえで、誤検知と未検知のバランスを適切に設定する必要があります。具体的には、重要度の高い異常については検知感度を高め、逆に比較的影響の小さい異常については誤検知を抑制する方向でチューニングを行うなど、きめ細かな調整が求められるでしょう。
情報セキュリティのリスク
異常値検出システムが取り扱うデータ量は膨大であり、このデータ量の大きさに比例して、情報セキュリティのリスクも高まっています。
製造工程で発生するデータには、設備の稼働状況や製品の品質情報など、企業にとって機密性の高い情報が数多く含まれます。これらの重要なデータが、通信経路での傍受や、クラウドストレージからの情報漏洩、システムへの不正アクセスなど、様々な脅威にさらされているのです。特に近年は、企業を標的としたサイバー攻撃が増加傾向にあり、仮にデータが流出した場合、企業の競争力に深刻な影響を及ぼすでしょう。
重要なのは、システムと運用の両面からの包括的な対策です。システム面では、データの暗号化、通信経路のセキュリティ確保、厳格なアクセス権限管理などの技術的対策が基本となります。一方、運用面では、定期的なセキュリティチェックの実施、データバックアップ体制の構築、従業員への教育・訓練などが重要となるでしょう。
また、特に機密性の高いデータを扱う場合は、クラウドサービスの利用を最小限に抑え、自社のオンプレミス環境でシステムを構築・運用することも視野に入れるべきです。ただし、この場合は自社でのセキュリティ管理体制の整備が前提となります。
導入・運用コストの大きさ
異常値検出のためのシステム導入には相応の投資が必要となります。導入および運用にかかるコストを正しく把握し、効果的な投資計画を立てることが導入成功の鍵となるのです。
初期投資としては、センサーや計測機器の導入費用、システム開発費用が大きな割合を占めます。特に既存の製造設備にセンサーを新設する場合、設備改造や配線工事などが必要となる場合があり、想定以上のコストが発生する可能性も。また、データを保存・処理するためのストレージやサーバー環境の構築も必要です。
また、運用段階では、システムの保守・メンテナンス費用、データストレージの使用料、そして何より重要なのが、人材育成にかかるコストです。異常値検出システムを効果的に運用するためには、データ分析のスキルを持つ人材や、システムの保守管理を行う技術者の育成が不可欠なのです。
これらのコストを最適化するためには、まず投資対効果(ROI)を見極めた上で、段階的な導入を検討することが有効です。重要な製造設備から順次導入を進めることで、初期投資を分散させることができます。また、クラウドサービスの活用により、自社でのシステム構築・運用にかかるコストを抑制することも可能でしょう。さらに、既存の設備やセンサーを最大限活用することで、新規導入コストを最小限に抑えることができます。
予測過程の不透明さ
システムが導き出した予測の「説明可能性」を確保することは、導入の成否を左右する重要な課題です。特に製造現場では、長年の経験に基づいて異常を察知してきた熟練作業者の信頼を得ることが、システム定着のカギとなるでしょう。
AIや機械学習を用いた異常値検出システムは、しばしば「ブラックボックス」と呼ばれるように、なぜその判断に至ったのかが不透明になりがちです。この不透明さは、予測結果の信頼性への疑問を生み、現場作業員のシステム受け入れを阻む原因となります。それだけでなく、誤検知が発生した際の原因究明や、システムの改善点の特定が困難になることも考えられます。
この課題に対しては、まず、異常値検出手法の選定段階から「説明可能性」を重視することが重要です。具体的には、ディープラーニングのような複雑な手法よりも、決定木や回帰分析など、より解釈しやすい手法を採用することで、予測根拠を明確にできる可能性があります。
さらに、予測結果を現場作業者に提示する際は、どのセンサーデータがどのように判断に影響したのかを、グラフや数値で可視化することが有効です。また、定期的な報告会や勉強会を通じて、システムの動作原理や判断基準を丁寧に説明することで、現場の理解と信頼を徐々に醸成していくことも有効でしょう。
異常値検出の応用事例
異常値検出システムは様々な業界で導入が進んでいます。ここでは実際の導入事例を知り、自社での導入可能性について検討してみましょう。
株式会社オプテージ
関西圏で個人向け光回線150万件超の加入件数を誇る株式会社オプテージでは、従来の閾値ベースでの監視では検知が困難な障害の発生に悩まされていました。そこで、機械学習を用いた異常検知を導入することにより、未検知なし、かつ誤検知を99%削減することに成功。さらにネットワークの急激なトラフィック減少を10分以内に検知可能に。これにより、システム運用効率と信頼性が大幅に向上しました。
キューピー株式会社
キユーピー株式会社では、食品工場の製造工程における異物混入や不良品検知に機械学習を導入しています。従来、従業員の目視によって夾雑物混入を検査していましたが、ディープラーニングを用いた画像解析技術を活用することで、製品の良・不良を瞬時に判別するシステムを導入。これにより、人間の目視では難しい微細な異常を高精度で検出することが可能になり、品質管理の効率化を実現しました。
ナブテスコ株式会社
産業用機械の部品製造分野で高いシェアを誇るナブテスコ株式会社では、風力発電機の旋回部分の監視に機械学習を導入。異常検知システムの導入により、旋回部の負荷状態をリアルタイムで可視化し、保守作業の効率化を実現しました。また、過去に発生した異常状態の詳細な情報を、履歴から瞬時に閲覧することができるようになりました。
エムニの異常検知AI応用事例
エムニは、東京都庁が主催する現場対話型スタートアップ協働プロジェクトに採択され、下水道管再構築工事の設計書確認作業において、AIを活用したチェック機能を開発いたしました。従来は、設計書の確認作業を人力で行っており、チェックマンに相当な負荷がかかっていました。そこで将来的な人員不足も考慮してAIを活用し、設計書の自動チェック機能を実装。具体的には、AI-OCRによって設計書のテキスト情報を読み取り、AIチェックマンが誤りの可能性がある箇所を自動でハイライトする仕組みを構築しました。
現場対話型スタートアップ協働プロジェクトとは、多彩な課題を抱える都政現場にスタートアップを呼び込み、行政と対話を重ねることで解決策を模索しながら課題克服を図る取り組み。
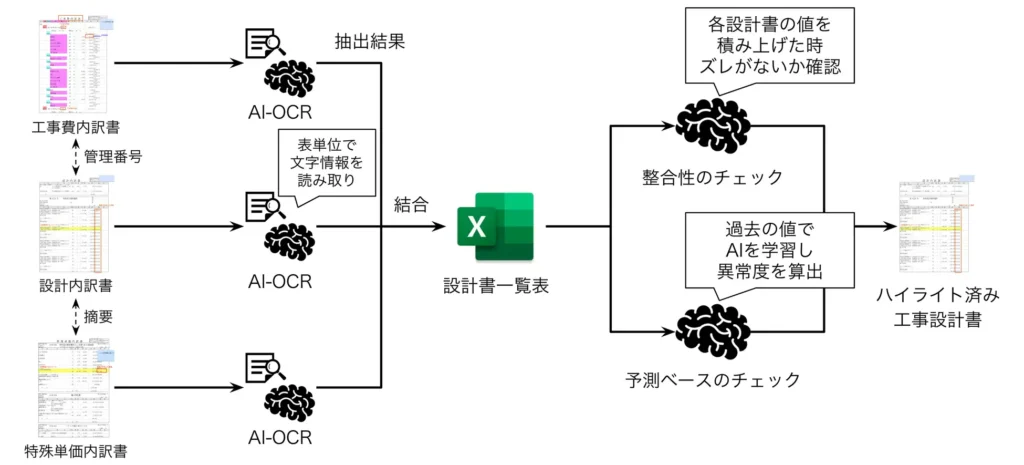
引用:株式会社エムニ、東京都庁現場対話型スタートアップ協働プロジェクトに採択
まとめ:異常値検出システムが実現する製造現場の未来
24時間365日、休むことなく設備を監視し、故障の予兆を検知し、ベテランの勘と経験をデジタルの力で継承する。これまで「人の目」と「経験」に頼ってきた製造現場の監視・保全業務を、異常値検出システムは大幅に効率化します。さらに、若手従業員の育成や働き方改革、経営判断の支援まで、幅広い効果が期待されます。一方で、データ収集や精度確保、設備投資コストなど、乗り越えるべき課題が多いことも事実です。
エムニでは、製造業に特化し、製造業が抱える課題に対して、企業様と伴走しながら、迅速かつ的確なAIソリューションの開発を行っております。無料でのデモ開発も行っておりますので、まずは無料相談からお問い合わせくださいませ。

